To all those who needs uninterrupted webservice here is an article that describes basic settings of how Linux Fail-over Clustering can be done using linux servers .
For this purpose we can use any Red-Hat distribution and another utility called Heartbeat.
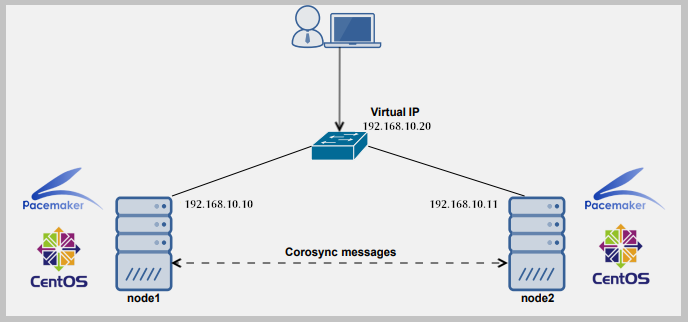
The heartbeat service provides the basic functions required for the HA system. In a cluster environment, a high availability (HA) system is responsible for starting and stopping services, mounting and dismounting resources, monitoring the system availability in the cluster environment, and handling the ownership of the virtual IP address that’s shared between cluster nodes.
The most common cluster configuration is called standby configuration, as described here. In the standby cluster configuration, one node performs all the work while the other node is idle. Heartbeat monitors health of particular service(s) usually through a separate Ethernet interface used only for HA purposes using special ping. If a node fails for some reason, heartbeat transfers all the HA components to the healthy node. When the node recovers, it can resume its former status.
Installing and Configuring
First of all install heartbeat in a centos machine.
[bash]
yum install -y heartbeat
[/bash]
To test High Availability Linux, you need a second Ethernet adapter devote to heartbeat on each nodes. Install the Apache Web server and the heartbeat program on both nodes.
The configuration files for heartbeat are not in place when the software is installed. You need to copy them from the documentation folder to the /etc/ha.d/ folder:
[bash]
cp /usr/share/doc/heartbeat*/ha.cf /etc/ha.d/
cp /usr/share/doc/heartbeat*/haresources /etc/ha.d/
cp /usr/share/doc/heartbeat*/authkeys /etc/ha.d/
[/bash]
Imagine you have two servers in a famous Datacenter and owns few public IP’s. In the /etc/hosts file you must add hostnames and IP addresses to let the two nodes see each other. In my case it looks like this:
[bash]
201.200.100.1 node1.www.sparksupport.com node1
201.200.100.2 node2.www.sparksupport.com node2
127.0.0.1 localhost.localdomain localhost
[/bash]
The two nodes will have same gateway IP and that will be set by Datacenter. For our example let node1 be primary and node2 backup or secondary. The primary will run an extra IP address (assigned using IP aliasing) and with that IP you will have to configure your webserver. Now configure these IP’s on eth0 and eth1 can be configured with private IP address for the use of hearbeat. The node1 and node2 should be connected using a crossover cable across these second Ethernet Card eth1.
Now ifconfig on node1 should provide following results.
[bash]
eth0 inet addr:201.200.100.1 Bcast:201.200.100.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:18617 errors:0 dropped:0 overruns:0 frame:0
TX packets:14682 errors:0 dropped:0 overruns:0 carrier:0
collisions:3 txqueuelen:100
Interrupt:10 Base address:0x6800
eth0:0 Link encap:Ethernet HWaddr 00:60:97:9C:52:28
inet addr:201.200.100.5 Bcast:201.200.100.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:10 Base address:0x6800
eth1 Link encap:Ethernet HWaddr 00:60:08:26:B2:A4
inet addr:192.168.1.2 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:15673 errors:0 dropped:0 overruns:0 frame:0
TX packets:17550 errors:0 dropped:0 overruns:0 carrier:0
collisions:2 txqueuelen:100
Interrupt:10 Base address:0x6700
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:3924 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:38 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
[/bash]
And ifconfig on node2 should provide the following results.
[bash]
eth0 inet addr:201.200.100.2 Bcast:201.200.100.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:18617 errors:0 dropped:0 overruns:0 frame:0
TX packets:14682 errors:0 dropped:0 overruns:0 carrier:0
collisions:3 txqueuelen:100
Interrupt:10 Base address:0x6800
eth1 Link encap:Ethernet HWaddr 00:60:08:26:B2:A4
inet addr:192.168.1.3 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:15673 errors:0 dropped:0 overruns:0 frame:0
TX packets:17550 errors:0 dropped:0 overruns:0 carrier:0
collisions:2 txqueuelen:100
Interrupt:10 Base address:0x6700
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:3924 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:38 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
[/bash]
We will have to edit three more files and these files should be exactly the same in both nodes.
[bash]
/etc/ha.d/ha.cf
/etc/ha.d/haresources
/etc/ha.d/authkeys
[/bash]
Next, modify the configuration file /etc/ha.d/ha.cf. Edit the following entries in order to get heartbeat to work:
[bash]
logfile /var/log/ha-log #where to log everything from heartbeat
logfacility local0 #Facility to use for syslog/logger
keepalive 2 # the time between the heartbeats
deadtime 30 #how long until the host is declared dead
warntime 10 #how long before issuing “late heartbeat” warning
initdead 120 # Very first dead time (initdead)
udpport 694 #udp port for the bcast/ucast communication
bcast eth1 #on what interface to broadcast
ucast eth1 192.168.1.1 #this is a 2-node cluster, so no need to use multicast here
auto_failback on #we want the resources to automatically fail back to its primary node
node node1.www.sparksupport.com #the name of the first node
node node2.www.sparksupport.com #the name of the second node
[/bash]
The ucast in node2 should be ucast eth1 192.168.1.2
The next file is /etc/ha.d/haresources with the following entry
[bash]
node1.www.sparksupport.com 201.200.100.5 httpd
[/bash]
The last heartbeat-related file is /etc/ha.d/authkeys with the entry.
[bash]
auth 1
1 crc
[/bash]
The file should be readable only by root user for security reasons
[bash]
chmod 600 /etc/ha.d/authkeys
[/bash]
Now configure httpd.conf with the public IP address.
[bash]
Listen 201.200.100.5:
DocumentRoot “/home/spark/www”
[/bash]
It’s important for the Apache service to not start automatically at boot time, since heartbeat will start and stop the service as needed. Disable the automatic start with the command (on a Red Hat-based system):
[bash]
chkconfig httpd remove
[/bash]
Make sure you have the same Apache configuration on both nodes.
Testing Fail-over cluster(Linux Fail-over Clustering)
At this point we’re done with configuration. Now it’s time to start the newly created cluster. Start the heartbeat service on both nodes:
[bash]
/etc/init.d/heartbeat start
[/bash]
Watch the /var/log/ha-log on both nodes. If everything is configured correctly, you should see something like this in your log files:
[bash]
Configuration validated. Starting heartbeat 1.2.3.cvs.20050927
heartbeat: version 1.2.3.cvs.20050927
Link node1.www.sparksupport.com:eth1 up.
Link node2.www.sparksupport.com:eth1 up.
Status update for node node2.www.sparksupport.com: status active
Local status now set to: ‘active’
remote resource transition completed.
Local Resource acquisition completed. (none)
node2.example.com wants to go standby [foreign]
acquire local HA resources (standby).
local HA resource acquisition completed (standby).
Standby resource acquisition done [foreign].
Initial resource acquisition complete (auto_failback)
remote resource transition completed.
[/bash]
Now test the failover. Reboot the master server. The slave should take over the Apache service. If everything works well, you should see something like Linux Fail-over Clustering:
[bash]
Received shutdown notice from ‘node1.www.sparksupport.com’.
Resources being acquired from node1.www.sparksupport.com.
acquire local HA resources (standby).
local HA resource acquisition completed (standby).
Standby resource acquisition done [foreign].
Running /etc/ha.d/rc.d/status status
Taking over resource group 201.200.100.5
Acquiring resource group: node1.www.sparksupport.com 201.200.100.5 httpd
mach_down takeover complete for node node1.www.sparksupport.com
node node1.www.sparksupport.com: is dead
Dead node node1.www.sparksupport.com gave up resources.
Link node1.www.sparksupport.com:eth1 dead.
[/bash]
And when the master comes back online again, he should take over the Apache service:
[bash]
Heartbeat restart on node node1.www.sparksupport.comheartbeat
Link node1.www.sparksupport.com:eth1 up.
node2.www.sparksupport.com wants to go standby [foreign]
standby: node1.www.sparksupport.com can take our foreign resources
give up foreign HA resources (standby).
Releasing resource group: node1.www.sparksupport.com 201.200.100.5 httpd
Local standby process completed [foreign].
remote resource transition completed.
Other node completed standby takeover of foreign resources.
[/bash]
Conclusion Linux Fail-over Clustering
This is a basic setup you can increase the number of services. You should sync the data in primary and secondary nodes.